Setting up serialised, scheduled, retriable jobs with Resque
In a recent project I worked on at Icelab that used Resque to manage background jobs, I needed to implement job serialisation so that a dependent job would only be run if the job it depended on completed successfully. I also wanted to implement a schedule for these jobs to be run weekly, and given these jobs would be triggered automatically based on a schedule it was important to ensure they would be retried automatically in the event of failure. But first, some background on the project.
The project
The project was a bespoke publishing platform for an Australian university, to enable the university’s academics to publish long form articles on a variety of topics including Urban Planning, Legal Affairs and the Arts. As a means to promote the platform internally and encourage participation, the team from the university tasked with managing it wanted to collect detailed analytics regarding the performance of articles and authors and, using this data, distribute a weekly report to authors providing them with a top-level overview of the performance of their articles across a number of metrics (including total visitors, page views and complete reads of their articles).
The logic flow of the application went something like this:
- Retrieve data for the previous week from the Google Analytics API
- Perform numerous background calculations with this data (e.g. calculate week-on-week variance for page views, rank authors by page views)
- Build and send an individually-tailored email report to each author
I’d added the logic for retrieving the data from the Google Analytics API as a previous piece of work so I won’t cover that here.
With the fetching of the data from the Google Analytics API underpinning this whole feature, it was critical that the subsequent steps would not be executed until this process was successful as otherwise the data presented in the emails would be incomplete at best, and completely unreliable at worst.
The solution
The app was already using Resque for running background jobs so it made sense to use it again here. Having decided to use Resque there were two main considerations: scheduling the jobs to retrieve the data from the GA API and send the emails, and how to recover in the event that either of these jobs failed. Resque doesn’t provide scheduling or retry functionality out of the box so this meant using some additional libraries. After a bit of hunting around, resque-scheduler and resque-retry seemed to fit the bill so that’s what I went with.
First up I added the required gems to the Gemfile:
# Gemfile
gem "resque-retry"
gem "resque-scheduler"
As the app was already using Resque, I only needed to tweak the existing configuration to load the resque-scheduler related dependencies:
# lib/tasks/resque.rake
require "resque/tasks"
require "resque/scheduler/tasks"
# config/initializers/resque.rb
require "resque"
require "resque/server"
require "resque-scheduler"
require "resque/scheduler/server"
Resque.redis = Redis.new(url: ENV["REDIS_URL"])
Resque.schedule = YAML.load_file("#{Rails.root}/config/resque_schedule.yml") || {}
The resque-scheduler and resque/scheduler/server dependencies are needed to add a Schedule tab to the resque-web UI (see the resque-scheduler README for more detail).
I then added a resquescheduler process to Procfile to run the resque:scheduler rake task:
# Procfile
resque: QUEUE=* bundle exec rake environment resque:work
resquescheduler: QUEUE=* bundle exec rake environment resque:scheduler
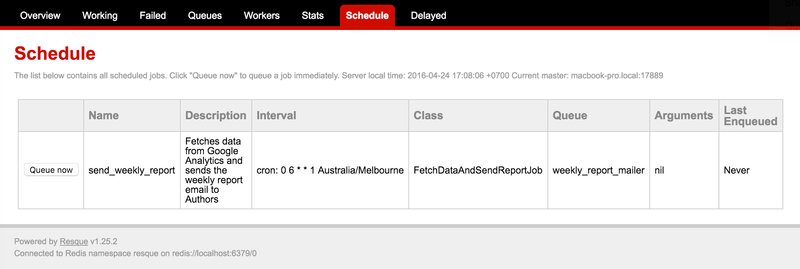
The next step was to configure the schedule. In this example the FetchDataAndSendReportJob job will be run every Monday at 0600 Melbourne time:
# config/resque_schedule.yml
send_weekly_report:
cron: "0 6 * * 1 Australia/Melbourne"
class: FetchDataAndSendReportJob
queue: weekly_report_mailer
description: Fetches data from Google Analytics and sends the weekly report email to Authors
Next I needed to modify the existing jobs to use resque-retry. One caveat I discovered here was that resque-retry and ActiveJob appear to not work together (I wasn’t able to able to get the retry attempts for a job to run when it inherited from ActiveJob::Base).
First the job to retrieve the data from the Google Analytics API:
# jobs/fetch_data_and_send_report_job.rb
require "resque-retry"
class FetchDataAndSendReportJob
extend Resque::Plugins::Retry
@queue = :weekly_report_mailer
@retry_limit = 3
@retry_delay = 20
def self.perform
# Fetch data from Google Analytics
end
def self.after_perform
SendReportJob.perform(author)
end
end
This job will be retried up to 3 times (so a total of 4 attempts will be made to run it successfully) at 20 second intervals. This job is also responsible for enqueueing the job to send the emails (SendReportJob) so this will not occur unless the required data is successfully retrieved from the Google Analytics API.
Finally, the job to send the emails to authors:
# jobs/send_report_job.rb
require "resque-retry"
class SendReportJob
extend Resque::Plugins::Retry
@queue = :weekly_report_mailer
@retry_limit = 3
@retry_delay = 10
def self.perform(author)
# Call the mailer method to send the email
end
end
The resque-retry plugin is again used here to allow 3 retry attempts at sending the emails.
And that’s it. This may be a somewhat naive solution as I’m still getting my feet wet with Resque, however it provides at least some resiliency in the event that something goes wrong (for example if the Google Analytics API is temporarily unavailable), rather than the whole workflow simply falling over.